香港阿里云服务器连接不常见原因排查与恢复步骤

概述:最好、最佳、最便宜的连接保障策略
当你的香港阿里云服务器出现连接异常时,既要考虑最好的高可用方案(多可用区+负载均衡+CDN),也要兼顾成本与性价比。对于追求最佳稳定性的用户,推荐使用阿里云SLB、跨可用区备份与自动化监控;而追求最便宜部署的场景可以选择小规格ECS、按量付费并启用基础带宽包与Cloud Firewall的免费策略。本文聚焦连接不常见原因的排查与恢复步骤,帮助你在不同预算下快速恢复业务。
不常见连接故障的总体分类
除了常见的安全组、端口未开放或服务未启动外,不常见的原因包括虚拟交换机(vSwitch)/路由表错配、弹性公网IP(EIP)漂移、物理链路BGP异常、MTU或TCP MSS不匹配、内核路由表或网卡驱动异常、阿里云侧的区域性网络故障,以及DNS解析被污染或误配置等。
网络层面排查要点
优先从实例内部排查:使用 ping、traceroute、tcptraceroute、ss、ip a、ip route 等命令确认网卡、路由和连通性。注意观察MTU大小和丢包率,若发现ICMP通且TCP不通,检查防火墙和TCP MSS。若出现路由黑洞或跨区域不通,使用traceroute定位跳点,判断是实例侧、阿里云网络还是上游ISP问题。
云控制台与VPC配置检查
登录阿里云控制台检查安全组、网络ACL、VPC路由表、子网(vSwitch)与EIP绑定关系。常见不常见问题有安全组规则误设为仅允许内网或误设白名单、EIP被回收或重新分配、路由表中缺少到Internet网关的0.0.0.0/0条目。必要时可尝试解绑并重新绑定EIP,或在不同子网创建临时ECS做对比测试。
操作系统与服务端配置检查
检查系统日志(/var/log/messages、/var/log/syslog、dmesg)以发现驱动或内核错误,确认网络服务(如sshd、nginx)是否在监听预期端口(使用 ss -tnlp)。若网卡不显示或获取不到IP,可尝试重启网络服务(如 systemctl restart network 或 dhclient eth0),必要时重启ECS实例或重置网卡驱动。
安全设备与防火墙干扰
除了实例内防火墙(iptables/nftables/firewalld),还需确认阿里云的云防火墙或第三方WAF策略是否在阻断流量。规则误判或频繁触发策略会造成间歇性连接失败。建议临时放宽规则或查看云防火墙日志,确认是否为策略阻断,并基于日志调整白名单或频率限制。
上游网络与ISP问题
有时问题不在阿里云而在上游ISP或骨干链路,例如BGP收敛延迟、链路抖动或DDoS攻击导致的流量清洗。通过traceroute定位到哪个AS/路由器出现问题,必要时联系阿里云技术支持并提供traceroute与PCAP抓包结果,阿里云可协助联系骨干ISP进行处理。
详细恢复步骤(推荐顺序)
1) 保存现场:记录时间点、错误信息、traceroute与ping结果、syslog日志与安全组截图。 2) 实例内快速修复:检查服务状态并重启服务,确认端口监听;检查网卡与路由并重启网络。 3) 控制台层面修复:检查并临时放通安全组/网络ACL,重新绑定EIP或重设路由表。 4) 回退或重建:若无法恢复,使用备份快照恢复到新ECS并绑定原EIP或DNS切换至备用实例。 5) 提交工单:若怀疑阿里云链路或区域故障,及时提交工单并附上traceroute与抓包数据,申请阿里云介入。
预防建议与监控策略
建立多AZ部署、使用SLB做健康检查、设置自动化备份与快照、启用阿里云监控告警(带宽、丢包、延迟、CPU)并结合外部合成监控(从多个节点探测香港ECS),能最大限度减少单点故障导致的连接中断。此外,制定演练流程并记录故障模板以便快速响应。
结语
针对香港阿里云服务器的连接不常见原因,系统化的排查与有序的恢复步骤能显著缩短故障时间。遵循“保存现场→实例层快速修复→控制台核查→回退或重建→必要时提交工单”的流程,同时结合成本考量选择合适的高可用或廉价方案,能在保证可用性的前提下降低费用与风险。
-

78云服务器香港价格:最低价格一览
78云服务器是一家提供全球云计算服务的领先企业,拥有多个机房分布在全球各地,其中包括香港机房。香港机房位于亚洲金融中心,提供高性能、可靠稳定的云服务器服务。对于需要在中国大陆地区有较低延迟的用户来说,选择香港机房是一个理想的选择。 1. 低延迟:香港机房在中国大陆地区具有较低的延迟,可以提供更快的访问速度。 2. 稳定可靠:香港机房采2025年3月17日 -

腾讯云香港轻量服务器 IP 段的使用与优化建议
作为一项高效的云计算服务,腾讯云香港轻量服务器在全球范围内受到越来越多用户的青睐。本文将详细探讨其IP 段的使用情况,并提供一些优化建议,帮助用户更好地管理和利用这一资源。通过合理的配置与优化,用户可以提升服务器的性能与安全性,确保业务的高效运行。 腾讯云香港轻量服务器的IP段有哪些特点? 腾讯云香港轻量服务器的IP 段具有多种特点。首先,其2025年9月3日 -

香港有云服务器提供吗?
香港有云服务器提供吗? 随着互联网的发展,云计算技术逐渐成为各行各业的热门选择。云服务器作为云计算的重要组成部分,为用户提供了灵活、安全、可靠的服务器资源,受到越来越多企业和个人的青睐。在香港这样一个国际化大都市,是否有云服务器提供呢?让我们一起来探讨。 香港作为全球重要的金融和商业中心,拥有发达的信息技术产业和完善的网络基础2025年6月30日 -

工程师必读 百度香港云服务器ping值高的网络层排查技巧
工程师必读:网络层排查的三大精华 1. 精华一:先从ping值与丢包判断是不是链路问题,快速过滤应用与路由面故障。 2. 精华二:用Traceroute或MTR识别跳点延迟与抖动,定位到具体的ISP或中间节点。 3. 精华三:对照BGP与ISP对等策略,检查是否存在BGP不优或流量被劫持/绕路的情况。 当你的百度香港云服务器2026年5月25日 -

香港云服务器10元一年
香港云服务器10元一年 云服务器是一种基于云计算技术的虚拟服务器,它使用云计算技术将多个物理服务器组合在一起,以提供高可用性、灵活性和可扩展性。云服务器允许用户根据自己的需求动态分配计算资源,减少硬件设备的需求和管理成本。 香港作为亚洲的金融中心,拥有先进的互联网基础设施和通信网络。香港的云服务器提供商提供高性能的网络连接,低2025年3月16日 -

香港云服务器哪家性价比高
香港云服务器哪家性价比高 云服务器是一种基于云计算技术的虚拟服务器,它可以提供强大的计算和存储资源,适用于各种应用程序和网站。香港作为亚洲的金融中心,拥有稳定的网络环境和优质的数据中心设施,吸引了许多云服务器提供商进驻。然而,香港的云服务器市场竞争激烈,不同的提供商在性价比方面存在差异。本文将介绍香港云服务器市场上性价比较高的几家2025年4月26日 -

香港云服务器大厂:一站式云计算解决方案
香港云服务器大厂:一站式云计算解决方案 随着云计算技术的快速发展,越来越多的企业开始意识到云计算的重要性。云计算可以提供灵活、可扩展、高性能的计算资源,为企业的业务发展提供强有力的支持。然而,对于很多企业来说,搭建和维护自己的云服务器并不容易。在这个背景下,香港云服务器大厂应运而生,为企业提供一站式的云计算解决方案。 一站式云2025年2月16日 -
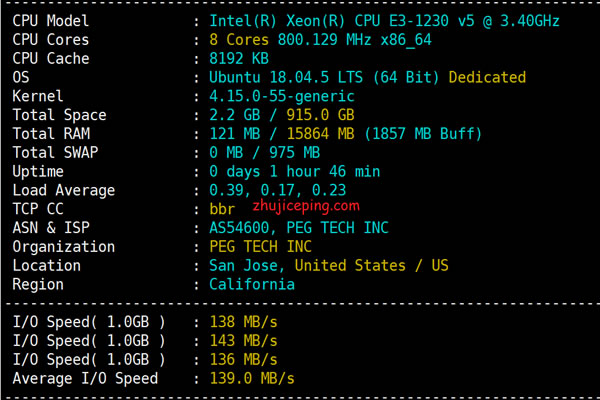
面向开发者的香港云服务器什么用途及常见部署场景分析
1. 香港云服务器对开发者的价值与适用场景概述 开发者为什么选香港节点:靠近中国大陆、国际出口灵活、政策与延迟平衡优良。 适用对象:SaaS 开发者、移动后端、跨境电商与媒体公司。 关键收益:低延迟到华南、快速访问国际 CDN、便于备案与合规。 主要限制:部分提供商带宽计费策略与 IP 资源限制需提前规划。 技术要点:支持 IPv4/IPv6、2026年4月19日 -

阿里云国际香港服务器开200m速度
阿里云国际香港服务器开200m速度 近日,阿里云宣布推出了200m速度的国际香港服务器,这一消息引起了广泛关注。这款服务器不仅提供了强大的性能,还具有稳定的连接速度,为用户提供了更好的上网体验。 这款国际香港服务器采用了最新的硬件设备,配备了高性能处理器和大容量内存,能够轻松应对高负载的情况。无论是进行大型网站的托管还是进行2025年7月13日