提升稳定性长期避免香港云服务器能访问吗的优化方法
在选择和维护香港云服务器时,大家关心的是哪种方案是“最好”、成本最低的“最便宜”以及在长期运行中如何确保稳定性与持续访问。本文基于实测与行业最佳实践,提出一套可执行的优化方法,既包含低成本入门策略,也包含用于生产环境的高可靠架构,帮助长期避免因单点或网络故障导致的不可访问问题。
评测一台香港节点云服务器的可用性,要从网络延迟、丢包率、带宽上行稳定性、实例规格、存储IO以及运营商链路冗余等维度入手。对长期< b>访问风险的判断应结合历史故障记录、地域链路质量与服务商SLA,形成可量化的可用性目标(如99.95%+)。
网络是影响香港云服务器是否能稳定访问的首要因素。建议选择多ISP链路或提供BGP多线的服务商,配置合适的出口带宽与突发带宽,并开启流量监控与QoS策略,避免带宽饱和导致的突发不可用。
“长期避免”单点故障最有效的方式是多可用区或多地域部署。即使主服务部署在香港,也应在华南或境外节点做异地备份、活动/被动切换或同城双活,实现故障自动漂移和最短恢复时间。
使用云服务商的负载均衡(或自己搭建LVS/HAProxy/NGINX)可以分散流量并实现健康检查。当香港实例不可用时,通过自动下线健康检查并将流量切换至备用节点,保证用户访问不中断。
对静态资源启用CDN可以显著降低对香港源站的压力,并改善全球用户的访问体验。CDN还能在源站故障时提供缓存回源策略,减少“无法访问”的影响面。
合理设置DNS TTL和启用智能DNS(如地理位置路由、健康路由)能快速将用户引导到可用节点。短TTL配合自动化健康检测,能在香港节点出现问题时迅速切换流量但又需权衡DNS查询成本。
香港节点面临的网络攻击可能导致短期或长期不可访问。建议使用云防火墙、DDoS防护与WAF,开启流量清洗与异常流量告警,结合黑名单与速率限制降低攻击面。
在实例操作系统层面进行TCP连接调优、keepalive参数配置、文件句柄数调整和异步IO优化,可提高并发处理能力与稳定性。定期打补丁、升级内核与驱动以避免已知漏洞或性能问题。
磁盘IO瓶颈和数据库单点故障常导致应用不可用。采用云盘快照、异地备份、主从/主主数据库复制和分片策略;关键业务启用多活或热备切换,保证数据可用性与恢复时间目标(RTO/RPO)。
完善的监控体系包括探针监控、主机和应用监控、链路监控。设置分级告警、自动化恢复脚本与运维Runbook,结合自愈能力(如自动重启、弹性伸缩)能显著缩短故障影响时长。
定期进行压力测试、故障注入与演练(Chaos Engineering)可以发现隐藏的单点和降级逻辑问题。通过演练检验切换流程与回滚机制,确保在真实故障中按预期执行。
最佳方案并不总是最贵:可以通过混合使用低成本冷备节点与少量高可用主节点、按需扩容和预留实例结合的方式,控制费用同时满足可用性需求。评估SLA、带宽计费和维护成本,选择最贴近业务需求的组合。
要长期避免香港云服务器无法访问,建议按优先级落地:1)选择多线BGP或多ISP,2)部署跨可用区和异地备份,3)引入负载均衡与CDN,4)强化DDoS/WAF防护,5)完善监控告警与自动化恢复。结合成本评估与定期演练,可最大化稳定性并降低长期不可用风险。
-

便宜的香港云服务器推荐
随着互联网的迅猛发展,越来越多的企业和个人开始意识到云服务器的重要性。云服务器不仅可以提供稳定可靠的服务,还可以降低成本。在云服务器市场中,香港云服务器备受关注,因为香港具有良好的网络基础设施和稳定的政治环境。本文将介绍几款价格便宜且性能出色的香港云服务器,帮助您选择最适合您需求的云服务器。 阿里云是中国领先的云计算服务提供商,也是香港云2025年4月8日 -

香港4核8G500硬盘云服务器的性价比分析
在众多云服务器中,香港4核8G500硬盘云服务器因其高性价比而受到广泛关注。本文将详细分析这款服务器的性能、稳定性、适用场景及价格优势,最终推荐德讯电讯作为优质服务提供商,让用户在选择时有更清晰的方向。 性能评估 香港的4核8G云服务器在性能上表现非常出色,尤其适合中小型企业和初创团队。4核的CPU能够保证多任务处理的流畅性,而8G的内存则为2025年12月22日 -

如何选择适合的云码数洲香港服务器
选择适合的云码数洲香港服务器是搭建网站、应用程序和在线服务的关键一步。本文将深入探讨选择服务器的几个重要因素,包括性能、稳定性、安全性和客户支持等,并推荐德讯电讯作为值得信赖的服务提供商,帮助您确保您的在线业务顺利运行。 性能与带宽 在选择云码数洲香港服务器时,性能是一个不可忽视的因素。您需要考虑服务器的处理器、内存和存储速度等硬件配置,这些2026年2月2日 -

阿里云香港服务器支持SS吗
阿里云香港服务器支持SS吗 Shadowsocks(简称SS)是一种安全的网络代理工具,能够加密网络连接,保护用户隐私。它通过混淆技术,将网络流量伪装为正常的HTTPS流量,有效避免被墙和封锁。SS因其高效、稳定和安全的特点,受到广大网民的喜爱。 阿里云是国内领先的云计算服务提供商,拥有全球分布的数据中心,2025年3月1日 -

香港绕线清洗云服务器,提升性能效能!
香港绕线清洗云服务器,提升性能效能! 在云计算时代,云服务器扮演着重要角色,为企业提供高效、灵活的数据存储和计算能力。然而,长时间运行的云服务器也会因为灰尘和脏污积累而降低性能,甚至导致故障。绕线清洗可以有效解决这个问题,提升云服务器的性能和效能。 绕线清洗是通过专业设备和技2025年3月30日 -

阿里win云香港服务器:速度快稳定,提供专业云计算服务
阿里win云香港服务器:速度快稳定,提供专业云计算服务 阿里win云是阿里巴巴集团旗下的云计算服务提供商,致力于为全球客户提供高性能、高可靠的云计算服务。阿里win云在香港地区设有服务器中心,为香港及周边地区的客户提供稳定快速的云计算服务。 香港作为国际金融中心,拥有优越的网络基础设施和通信环境。选择香港服务器可以获得2025年7月4日 -
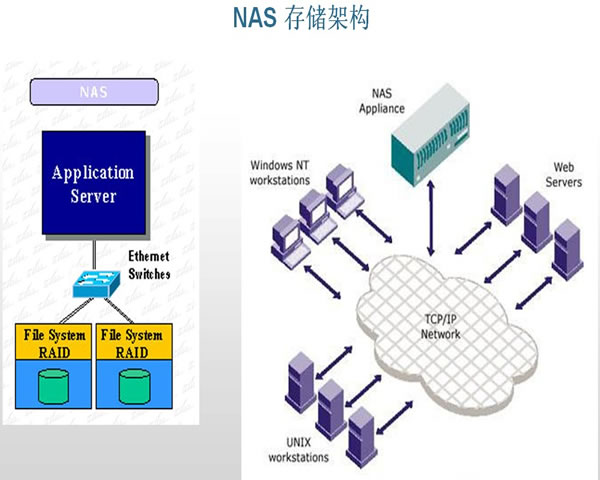
腾讯云香港服务器中转的操作流程与注意事项
在当今互联网时代,云服务器已经成为企业和个人用户搭建网站、进行数据存储和处理的重要工具。腾讯云作为国内领先的云服务提供商,其香港服务器凭借低延迟、高稳定性等优势,受到广泛的欢迎。为了帮助用户更好地使用腾讯云香港服务器进行中转,本文将详细介绍其操作流程与注意事项。 首先,我们来了解什么是服务器中转。服务器中转指的是通过设置中转服务2026年2月18日 -
4核8G香港华为云服务器适合哪些业务需求
随着互联网技术的发展,越来越多的企业和个人开始重视服务器的选择。尤其是香港华为云服务器,以其高效、稳定的性能,受到了广泛的关注。本文将深入探讨4核8G香港华为云服务器适合的业务需求,以及如何选择合适的服务器来满足这些需求。 首先,我们来了解一下4核8G香港华为云服务器的基本配置。该服务器搭载了4个CPU核心和8GB内存,2025年9月30日 -

双12阿里云香港服务器特惠活动详解不可错过
随着双12的到来,阿里云推出了一系列香港服务器的特惠活动,吸引了众多用户的关注。在这次活动中,用户不仅能够以优惠的价格获得高性能的服务器,还可以享受到多种增值服务。尤其是在当前网络技术日益发展的背景下,选择合适的服务器显得尤为重要。本文将详细解析此次阿里云的特惠活动,并推荐德讯电讯作为最佳选择。 阿里云香港服务器特惠活动概述 阿里云香港服务器2025年10月31日